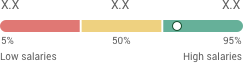Job Description
Job Title: Data Engineer/MLOps;
Location: Remote;
Payment: in USD;
Department: Engineering/Data Science;
Company Overview:
We are a forward-thinking organization in Australia leveraging data and technology to drive innovation. We seek a skilled data engineer to design, build, and maintain scalable data infrastructure, enabling advanced analytics and machine learning solutions.
Key Responsibilities:
- Data Pipeline Development: Design and implement robust ETL/ELT pipelines for processing structured/unstructured data.
- Python Programming: Develop Python-based tools, scripts, and APIs to automate workflows and integrate systems.
- Machine Learning Integration: Collaborate with data scientists to deploy ML models into production environments.
- Containerization & Orchestration: Use Docker and Kubernetes to containerize applications and manage scalable deployments.
- Cloud Infrastructure: Optimize data storage, processing, and deployment on platforms like AWS, GCP, or Azure.
- Data Governance: Ensure data quality, security, and compliance with industry standards.
- Collaboration: Work with cross-functional teams to translate business requirements into technical solutions.
- Performance Optimization: Tune databases, queries, and pipelines for efficiency and scalability.
- Monitoring & Maintenance: Implement logging, alerting, and troubleshooting for data systems.
- Documentation: Maintain clear technical documentation for architectures and processes.
Requirements:
- 3+ years of data engineering experience.
- Python Proficiency: Expertise in Python libraries (Pandas, NumPy, Airflow, FastAPI) and OOP principles. Experience in writing tests in Python is a **MUST-Have**.
- ML Frameworks: Familiarity with TensorFlow, PyTorch, or scikit-learn.
- Containerization: Hands-on experience with Docker and Kubernetes.
- ETL/Data Warehousing: Knowledge of tools like Apache Spark, Kafka, or Snowflake.
- Cloud Platforms: Experience with AWS (S3, Redshift, Lambda) or Azure.
- MLOps: Experience with MLOps tools (MLflow, Kubeflow).
- Databases: SQL (PostgreSQL, MySQL) and NoSQL (MongoDB, Cassandra).
- DevOps: CI/CD pipelines (Jenkins, GitLab CI), IaC (Terraform), and version control (Git).
- Problem-Solving: Ability to debug complex systems and deliver scalable solutions.
- Communication: Strong teamwork and stakeholder management skills.
Preferred/Nice-to-have Qualifications:
- Bachelor’s or Master’s in Computer Science, Data Science, or relevant work experience.
- Certifications in AWS/GCP, Kubernetes, or machine learning.
- Knowledge of distributed systems and real-time data processing.
- Contributions to open-source projects or public GitHub portfolio.
What We Offer:
- Competitive salary and benefits.
- Professional development opportunities.
- Collaborative, innovative culture.
- Impactful projects with cutting-edge tech.
How to Apply:
Submit your resume, GitHub profile, and a cover letter detailing your experience with Python, ML, and Kubernetes. We are an equal-opportunity employer.